来源 / Alter
每隔一段时间,大模型行业都会传出新的消息。
先是在9月中旬,OpenAI在没有预告的情况下发布了o1模型的预览版;不到半个月后,国内的智谱发布了若干更新模型,其中就包括新的基座大模型GLM-4-Plus,也是智谱当前最强大的模型。
国外围绕o1模型的讨论和场景探索还在继续,也让我们对GLM-4-Plus萌生了兴趣:智谱的最强模型到底有多强,能够解决哪些“悬而未决”的问题,又将带来什么样的影响?
01 全球前三的GLM-4-Plus,到底强在哪里
早在9月底的时候,国内人工智能权威机构清华大学基础模型研究中心就对国内外最具代表性的大模型进行了新一轮的综合性测评,评测数据集包含语义、对齐、代码、智能体、安全、数理逻辑、指令遵循等等。
按照清华大学基础模型研究中心发布的SuperBench九月综合榜单,GLM-4-Plus的综合能力排名前三,打破了过去被国外大模型垄断前三甲的局面,并在多个关键能力上保持了国际领先水平。
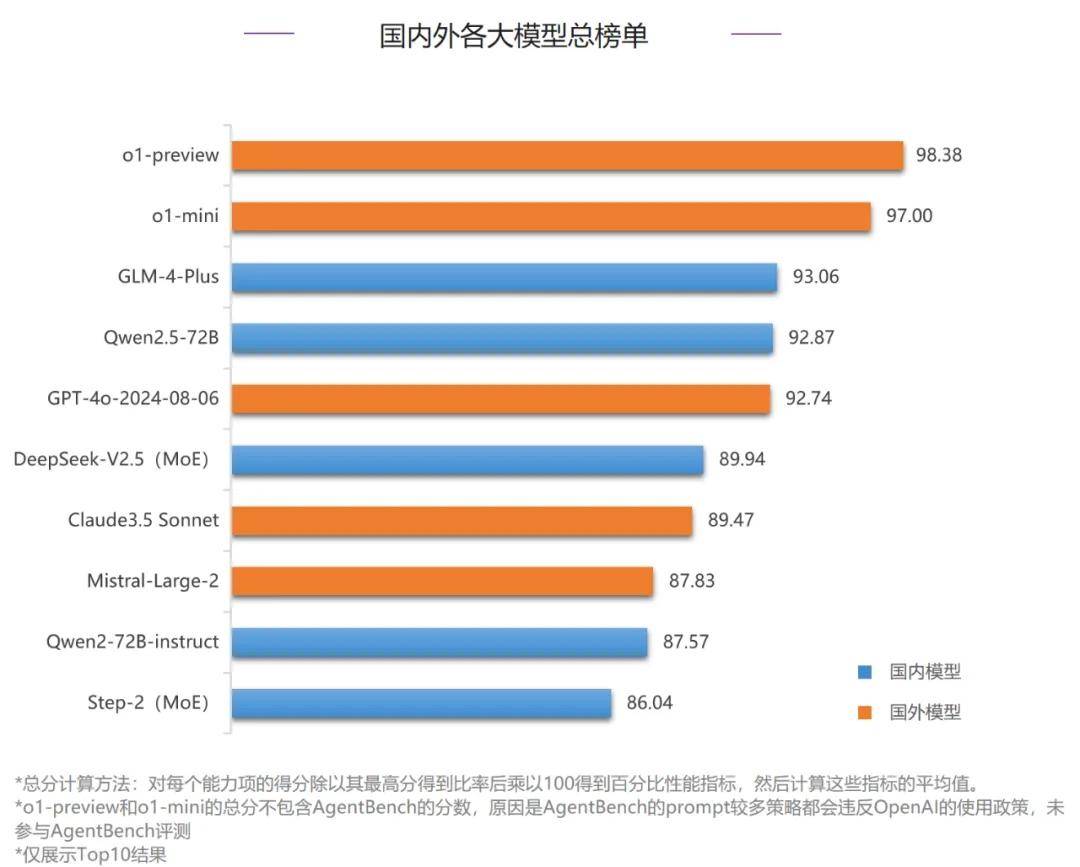
鉴于GLM-4-Plus在上线前已经内测了一段时间,期间有不少技术博主曾进行评测,我们关注到了三个层面的能力提升。
一是语言理解能力,通过大规模语料库训练和优化算法,GLM-4-Plus在处理复杂语义上的表现较其他模型更加出色。
借用测评博主toyama nao的结论:在难度较高的水果热量计算上(需要合理搭配水果,使总热量刚好在一个区间),大部分模型并没有真的懂题目,但GLM-4-Plus完全理解了题意,并采用逐步凑数的方法给出了正确答案,而且回答非常有“人味”,也是第一个在此题拿到满分的模型。
二是长文本能力,GLM-4-Plus支持128K上下文,凭借创新的记忆机制和分段处理技术,可以高效地处理大量文本信息。
我们之前曾让支持1M上下文的GLM-4-Long扮演了“书童”的角色,两分钟就能“熟读”50多万字的《国史大纲》。GLM-4-Plus在上下文长度上没有过于“激进”,而是基于精准的长短文本数据混合策略,取得了更强的长文本的推理效果,能够满足论文阅读、文章总结等更高频的应用需求。
三是时序问答和多轮对话能力,从单一的图像识别进化到对视频、图像的理解,并能针对单个视频进行多轮对话问答。
在智谱的Demo中,输入长达40秒的视频后,GLM-4-Plus可以准确理解并感知时间,精准定位到事件发生的时刻,然后在视频理解的基础上结合上下文进行对话,比如视频中的某个物体是在第几秒出现的、一共出现了几次,在智能安防、智能检测等场景中有着不可小觑的应用空间。
当然,以上只是我们比较感兴趣的几个能力,GLM-4-Plus的提升还体现在数学问题与代码计算、数据分析任务、机器翻译等方面,作为智谱全模型家族坚实的能力底座,堪称“六边形战士”般的存在。
02 比性能指标有感知的,是解决问题的能力
智谱提供了GLM-4-Plus的API接口,即使不懂技术原理、不会训练和微调,也可以调用API来解决工作中的实际问题,甚至动手开发出一个“智能体”,相比性能指标上的提升,有着更直接的价值感知。
因为日常工作需要处理大量的文字资料,限于大模型的语言理解和长文本能力,一些需求尚未被满足。于是我们在智谱的开放平台bigmodel上调用了GLM-4-Plus,并进行了针对性的场景测试:
第一个是财务报告的阅读和信息整理。
每次到了财报季,不少企业会公布一份长达几十页乃至上百页的报告,从头到尾阅读报告的内容,至少需要两个小时的时间,而且会习惯性忽略掉一些关键信息,所以我们将信息的整理工作交给了GLM-4-Plus。
我们上传了PDF文件,并输入“总结报告中的核心信息”的指令后,GLM-4-Plus迅速给出了我们想要的信息:

其中有两个让我们眼前一亮的细节处理:原报告中单位是“千美元”,GLM-4-Plus在输出的总结内容中,自动将单位换算成了“百万美元”;“晶圆代工”的收入和增长并未体现在图表中,仅在“管理层讨论与分析”的篇末提及,依旧被GLM-4-Plus精准“捕捉”。
第二个是围绕一些细节信息的对话问答。
文档阅读几乎是所有大模型主打的场景,仅仅是信息总结似乎不能证明GLM-4-Plus的能力有多强。所以我们进一步提升了难度,用一些“隐藏”在表格中的信息询问GLM-4-Plus,验证能否在数万字的报告中准确回答。
比如“目前有多少研发人员,30岁以下年轻人占比”的问题:

这个问题的迷惑性在于,表格中分别列举了2023年中和2024年中的研发人员数量,如果大模型不能准确理解上下文语义,很可能会给出2023年的数据。GLM-4-Plus的表现无疑可圈可点,不仅准确抓住了2024年的数据,给出了表格中没有的计算过程,而且将和问题对应的数字进行了加黑处理。
第三个是提炼核心信息并生成视频脚本。
除了归纳总结和信息检索,另一个刚需场景在于内容生成。我们尝试让GLM-4-Plus在报告的基础上提炼核心信息并生成视频脚本,在这个产品高度同质化的赛道上,GLM-4-Plus能否给出不一样的体验感呢?
结果再次超出了我们的预期。

原以为GLM-4-Plus会像很多大模型一样只是对信息进行简单的总结,最终给到的是一份90分的高分答卷,涵盖旁白、画面切换以及对插入图表、数据动画、“背景音乐选择轻快但不喧宾夺主的风格”等贴心建议,也让我们进一步理解了测评博主toyama nao为何会给GLM-4-Plus“有人味”的评价。
做一个总结的话,在GLM-4-Plus的帮助下,我们的工作效率至少提升了300%,考虑到智谱已经在智谱清言上线了视频创作智能体清影,30秒即可将任意文字生成视频,让我们对GLM-4-Plus的能力有了更多的期待:也许在不久后,只需上传一份财报,就能自动生成视频快讯。
03 人机交互的新范式,正被千万开发者定义
尽管我们的需求主要集中在内容创作上,但在体验了GLM-4-Plus的能力后,脑海中产生了这样一个认知:GLM-4-Plus提升的不单单是工作效率,人机交互的习惯正在朝不可逆的方向演变。
就像财报分析的过程,有别于过去逐段阅读、边看边记笔记的方式,GLM-4-Plus的多轮对话能力,让我们可以对着目录针对性提问,对整个工作流程和效率几乎是重塑的,一旦养成了习惯就不愿再重复过去的方式。
在整理素材的过程中,我们看到了GLM-4-Plus更多的应用场景:
有人将整理的大厂面试题库“喂”给了GLM-4-Plus,然后让模型生成针对性的面试题目。联想到智谱清言APP上线的“视频通话”功能,让AI扮演面试官的角色,进行一对一针对性训练并非没有可能。

也有人在挖掘GLM-4-Plus的数学问题与代码计算能力,在大模型的帮助下一步步厘清破题思路、给出准确的代码计算逻辑,进而帮助学生更好地分析和解答数学题,让GLM-4-Plus充当一对一家教。
更大范围的用户习惯,还需要和千万开发者一起培养。
比如智谱清言APP的“视频通话”功能,当AI有了“眼睛”后,帮我们解锁了作业辅导、产品介绍、游戏助手等一系列新体验。目前智谱已经开始内测GLM-4-Plus-VideoCall,将“视频通话”的魔法赋予越来越多的开发者。
以智能硬件为例,VR眼镜、智能音箱、家教学习机等产品都可以集成GLM-4-Plus-VideoCall,实现视频通话、语音多轮交互等跨模态能力,让电影《Her》中的场景从科幻走进现实。
同样的例子还有风头正劲的具身智能,在工业机器人等场景中,一旦拥有了视频分析与实时交互能力,将不再局限于程序设置的机械操作,极大提升工业机器人的自主操作能力,进一步解放生产力。
也就是说,GLM-4-Plus不只是“智能体”开发者的机会,还为硬件开发者提供了软硬协同的合作空间。
把视角再放大一些的话,苹果已经在iPhone 16系列上搭载了一颗独立的“相机键”,并在官方演示中将其定义为视觉AI的交互入口,在很大程度上预示了硬件创新的方向。
由此可以得出的结论是:智谱等大模型厂商已经向硬件开发者张开了怀抱,而苹果为首的硬件厂商正在积极迎接AI时代,一场“双向奔赴”将是可以预见的结局。
04 写在最后
令人兴奋的,远不止大模型的能力进阶和落地场景。
智谱在更新模型的同时,还同步释放了一波红利:10月份将赠送每位用户1亿tokens额度,并根据消耗梯度提供最高1折的API折扣。
原因并不难解释,GLM-4-Plus在能力提升的同时,成本也在大幅下降。大模型落地到千行万业的最后一道障碍,正在无形中“瓦解”。等待我们的,注定是一个被大模型改写的星光熠熠的时代。


















