作者:Alter
日前举办的华为全联接大会2022上,中国科学院自动化研究所所长徐波在演讲中提出了一个新观点:“多模态是人工智能迈向通用化的关键一步。”
学术界并不缺少大模型的“摇旗者”,特别是风头正劲多模态大模型,不少科学家曾在公开场合背书。不过以往谈及多模态的话题时,训练难度、算力成本常常是绕不过的痛点。倘若大模型注定只有少数企业拥有的“垄断资源”,哪怕一次次刷新人工智能的测试成绩,与“通用化”始终有着不小的距离。
为何徐波所长对多模态大模型的前景如此自信?坊间已经出现了学术维度的回答,或许还有一个新的视角,即产业应用侧的摸索与实践,比如40年前就尝试使用“专家系统”辅助判决的法律服务,正在多模态大模型的赋能下焕发出新的生机。
01 法律服务的双向痛点
其实很多人对“人工智能”已经不再陌生,原因并非是学术界或资本层面的沸腾,而是在产业深处的应用落地。
翻开几家人工智能企业的商业计划书,应用案例多半会占据相当长的篇幅。生产线上的质检流程、工程管理中的巡检巡查、市场需求侧的数据分析,早已被人工智能渗透、改造,在效率上远远超出了传统生产模式。
但这些机器“取代”人的场景,大多是不需要太多“思考”的重复性劳动,按照既定的算法规则就可以运行。可法律服务偏偏是非标准化的,不同案件的案由、案情、涉及的法律条文各不相同,而且结果还有着不可预见性,尤其考验从业者的经验法则、逻辑思维以及对情感的理解和处理能力。

因为有别于其他场景的行业特征,多年来普通人难以获取优质的法律服务。
站在法律求助者的立场上,寻求法律服务的渠道非常单一,甚至一些人根本不知道去哪里寻求法律服务。即使找到了律师求助,由于自身缺少对法律服务方能力的判断标准、缺少衡量法律服务费用的客观标准,整个过程就像是在“黑箱”中一样,导致很多人在“踩坑”后不愿意再去找律师解决问题。
而法律服务者也有自己的苦衷,市场上缺少全面的案源渠道和高效的筛选机制,难以精准匹配到目标客户,一旦双方在认知上的差异太大,不仅会产生过高的沟通成本,还很难让求助者对服务感到满意。一些基层法律服务者不得不花费大量时间重复低价值的琐碎工作,无形中推高了法律服务的机会成本。
为了解决法律服务中的“双向痛点”,行业内外可谓各出机杼。
早在上世纪80年代就有人将“专家系统”应用在了法律服务中,开发出了运用严格责任、相对疏忽和损害赔偿等模型来计算责任案件赔偿标准的法律判决辅助系统。等到新一轮人工智能浪潮的崛起,法律服务也是最早被赋能的场景之一,纷纷利用算法进行法规和判例的辅助检索,试图将法律工作者从浩如烟海的案卷中解放出来,进而能够将精力集中在更加复杂的法律推理工作中。
其中不乏一些“网红”级的案例。国内也出现了形形色色的法律机器人产品……
人工智能介入法律服务可以说是持续了几十年的夙愿,可惜在以往的案例中,人工智能的辅助价值非常有限,并未能消除已有的种种痛点。
02 人工智能正由浅入深
所有事物的演变都有一个由浅入深的过程,人工智能对法律服务的影响也是如此,注定是从边缘不断向法律服务的内核渗透。
把时间拨回到2021年7月份,基于昇腾AI的全球首个图文音三模态预训练模型“紫东.太初”正式发布,在武汉人工智能计算中心的算力支持下,首次实现了跨模态理解与跨模态生成能力。而“紫东.太初”多模态大模型的主导者,正是徐波担任所长的中国科学院自动化研究所。
5个月后的2021东湖国际人工智能高峰论坛上,中国科学院自动化研究所牵头的“多模态人工智能产业联合体”成立,试图基于多模态科研成果来进行应用创新孵化及产业聚合,解决一些悬而未决的长尾问题,陆续孵化出了多个行业解决方案,其中就包括武汉百智诚远科技有限公司研发的AI法律服务产品“法魔方”。
基于紫东.太初三模态大模型,百智诚远利用昇思MindSpore AI框架进行了AI法律服务的深入探索。
首先是数据的挖掘,汇聚了1.46亿条司法案例、1215万条法律法规、600亿条法律新闻和1亿则企业法律招投标信息,这些海量信息里不仅有结构化的数据,也有非结构化数据。由于“紫东.太初”多模态大模型采用了多层次多任务自监督预训练的学习方式,能够从大规模的无监督数据中挖掘隐含的监督信息进行训练,证明了多模态大模型的无限潜力。
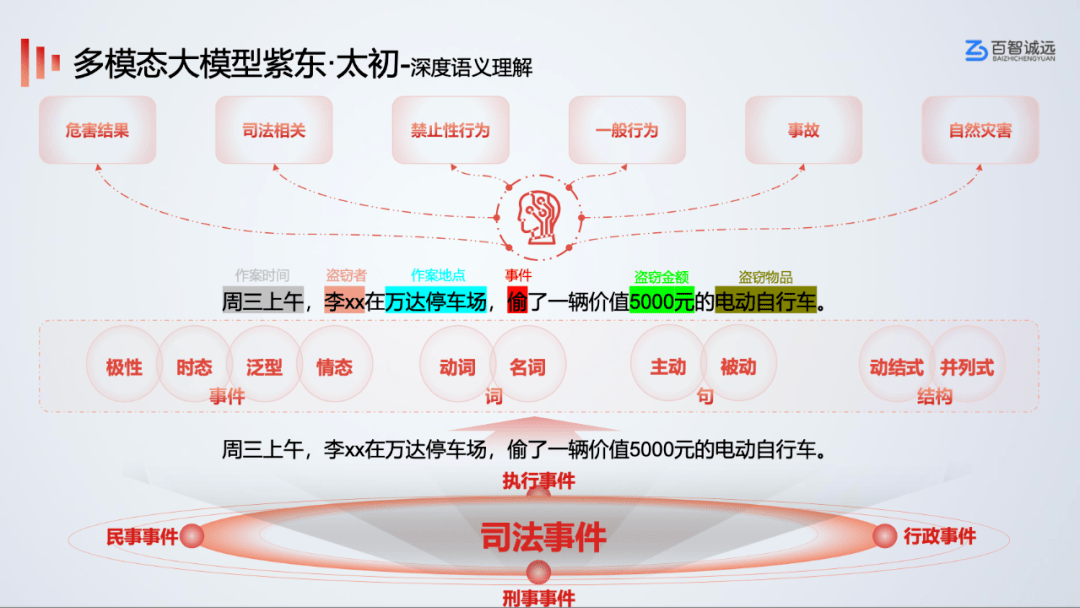
以深度语义理解为例,输入“周三上午,李XX在万达停车场,偷了一辆价值5000元的电动自行车”,“紫东.太初”可以自动识别出作案时间、盗窃者、作案地点、盗窃金额、盗窃物品等有效信息,并对事件性质、危害结果、相关司法案例等进行联想,形成了综合性的知识结构。
然后是场景的匹配,通过信息感知与知识推理、行业全景知识与内在联系产生应用知识、行业专家规则机器学习强化学习等训练,百智诚远的“法魔方”沉淀出了规律发现、辅助决策等能力,能够为律师律所、法院法官、咨询机构、企事业单位等不同场景提供法律数据、媒体资讯和咨询等服务。
比如面向法院法官的产品体系中,包含了类案检索、风险评估、法律法规查询、庭审大纲生成、电子卷宗整理、裁判文书生成、量刑参考等能力,人工智能不单单是替代机械性的重复劳动,逐渐延伸到了辅助决策、自主分析等深度应用,已经在某种程度上扮演了法律服务“智能助手”的角色。
其实在2017年前后,最高人民法院与国务院就曾出台文件,提出建设智慧法院的需求,促进人工智能在证据收集、案例分析、法律文件阅读与分析中的应用,实现法院审判体系和审判能力智能化。
多模态大模型的落地应用,不但填补了法律服务行业遗留多年的“坑”,也让外界深刻认识到了多模态的价值。
03 多模态大模型的胜利
需要回答的另一个问题在于:为何行业中存在多年的痛点,在多模态大模型的帮助下,似乎可以很轻松地解决?
先来复盘下以往算法模型的局限性:一是模型的功能单一,一个模型只能解决一个任务;二是模型的训练依赖于大量的样本,如果缺乏足够的样本支撑,训练也就无从谈起;三是人工智能模型的泛化能力差,不能应用于广泛的应用场景。
倘若不能摆脱“一专一能”的短板,人工智能的通用化很难实现,大模型潜力的爆发也就无从谈起。耗费海量的人力、物力去“炼”大模型,用于解决法律服务代表的长尾问题,无异于天方夜谭。
“紫东.太初”所瞄准的,正是常规大模型的局限性:通过将图像、文本、语音等不同模态数据实现跨模态的统一表征和学习,完成了从“一专一能”到“多专多能”的跨越,不仅可以实现跨模态理解,还能实现跨模态生成,做到了理解和生成两个最重要的认知能力的平衡,并首次实现了以图生音、以音来生图的功能。
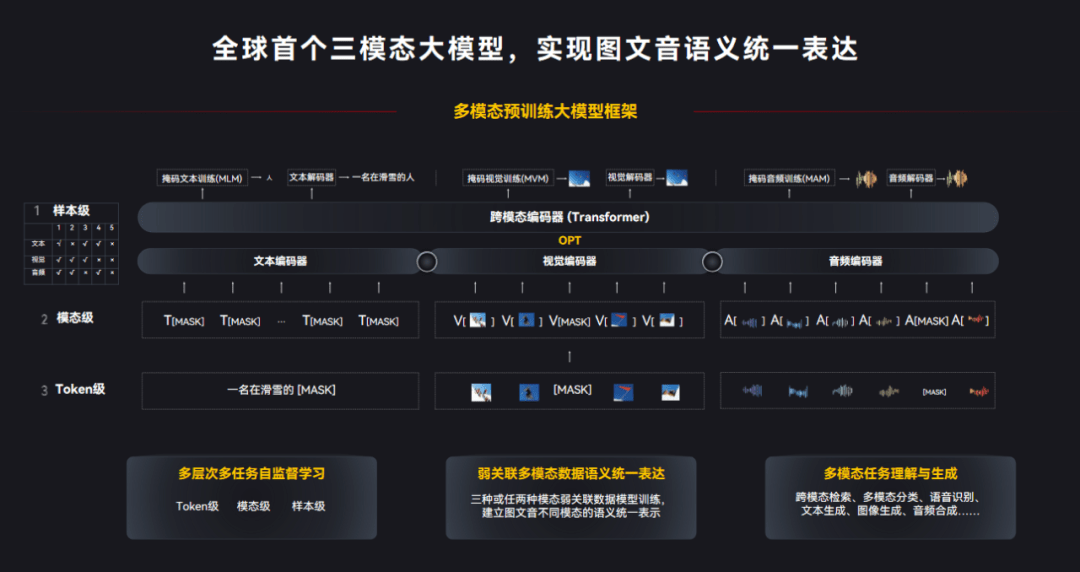
有了多模态大模型还不够,想要让千行百业里的企业可以用大模型来解决问题,还需要降低大模型的应用门槛。为了打通大模型产业应用的“最后一公里”,两个组织在其中扮演了不可或缺的角色。
一个是前面提到的“多模态人工智能产业联合体”,发布了“紫东.太初”大模型开放服务平台,支持模型的小样本训练和一键微调,并开源了目前业界最大的中文多模态训练数据集“紫东.太素”。用户先在大规模宽泛无标注数据上进行基础训练,再结合行业知识通过小样本学习微调,就可以满足多种应用任务的需要。
目前已经有40多家企业在平台上孵化了近60个解决方案,涵盖智能制造、智慧城市、智慧文旅等数十个行业。
另一个是“紫东.太初”等大模型的“幕后英雄”昇腾AI,参与构建了从规划、开发到产业化的大模型全流程使能体系。
典型的例子就是昇腾AI推出的大模型开发使能平台,简化大模型开发到部署的全流程:在大模型的开发上,提供了高性能Transformer API封装;在场景化适配上提供了微调套件,目前已经应用于“紫东.太初”大模型开放服务平台;在推理部署阶段,通过大模型部署套件提供自动的剪枝、蒸馏、量化等系列工具,可以在精度基本无损的情况下,实现模型十倍级压缩比,以支持模型的轻量化部署。
做一个总结的话,“紫东.太初”多模态大模型在产业应用中的“胜利”,所证明的不只是人工智能在法律服务中的潜力,也在潜移默化地改变外界对于大模型的态度,大模型绝不是什么军备竞赛,而是人工智能的研发范式和产业范式。
至少就目前来看,国内对于大模型的态度正在趋于理性:中国科学技术信息研究所正在协同产业界共同规划中国人工智能大模型地图,将统筹中国大模型有序发展;继智能遥感、多模态、智能流体力学等产业联合体后,电磁智能、智慧育种等产业联合体也在规划中,大模型落地的新方法、新模式逐渐有了雏形......
04 写在最后
1989年上线的科幻电影《回到未来2》曾预言:到了2015年,法律系统臻于完美,律师作为一种职业已经消失。
尽管电影中的预言“落空”了,人工智能对于法律服务的改变却是不争的事实。百智诚远代表的企业正在利用AI改写法律检索、合同审核、法律咨询、案件预测、诉讼策略选择等场景的运作逻辑,不断提升法律服务行业的智能化水平。
也许多年后再来回顾法律行业的演变,AI法律服务所承载的意义还会多一个维度,即多模态大模型的崛起。


















